1 Hadoop 安装与伪分布的搭建
2 Hadoop词频统计
此文章基于搭建好hadoop之后做的词频统计实验,以上是链接为搭建hadoop的教程
目录
1 HDFS 文件系统常用命令
2 词频统计实验准备工作
2.1 启动hadoop 关闭防火墙
2.2 查看图形化界面
2.3 文件上传
3 词频统计
3.1 方法一:使用hadoop自带的jar包文件
3.2 方法二:编写java程序打包jar包
1 HDFS 文件系统常用命令
# 显示HDFS根目录下的文件和目录列表
hadoop fs -ls /
# 创建HDFS目录
hadoop fs -mkdir /path/to/directory
# 将本地文件上传到HDFS
hadoop fs -put localfile /path/in/hdfs
# 将HDFS上的文件下载到本地
hadoop fs -get /path/in/hdfs localfile
# 显示HDFS上的文件内容
hadoop fs -cat /path/in/hdfs
# 删除HDFS上的文件或目录
hadoop fs -rm /path/in/hdfs
# 递归删除目录
hadoop fs -rm -r /path/in/hdfs
# 移动或重命名HDFS上的文件或目录
hadoop fs -mv /source/path /destination/path
# 复制HDFS上的文件或目录
hadoop fs -cp /source/path /destination/path
# 显示HDFS上文件的元数据
hadoop fs -stat %n /path/in/hdfs
# 设置HDFS上文件的权限
hadoop fs -chmod 755 /path/in/hdfs
# 设置HDFS上文件的所有者和所属组
hadoop fs -chown user:group /path/in/hdfs2 词频统计实验准备工作
2.1 启动hadoop 关闭防火墙
[root@hadoop ~]# start-all.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [hadoop]
Starting resourcemanager
Starting nodemanagers
[root@hadoop ~]# systemctl stop firewalld.service
2.2 查看图形化界面
查看ip地址
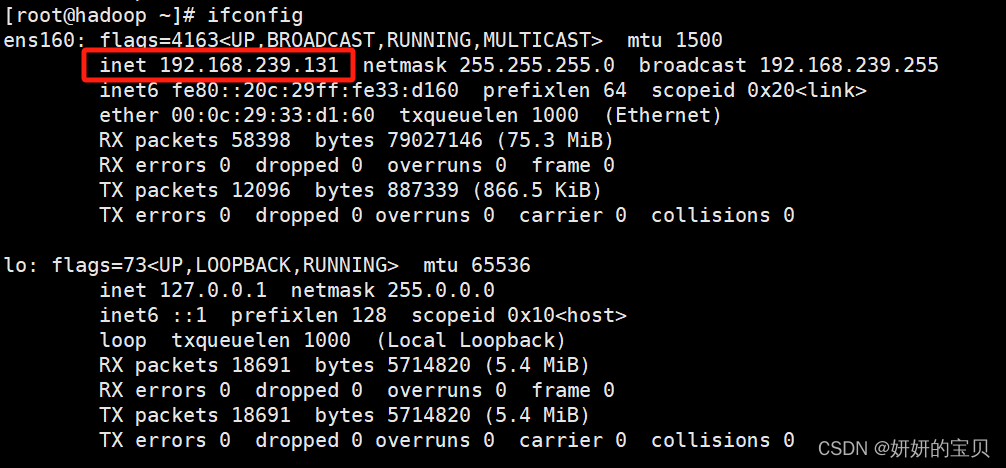
输入ip地址+9870
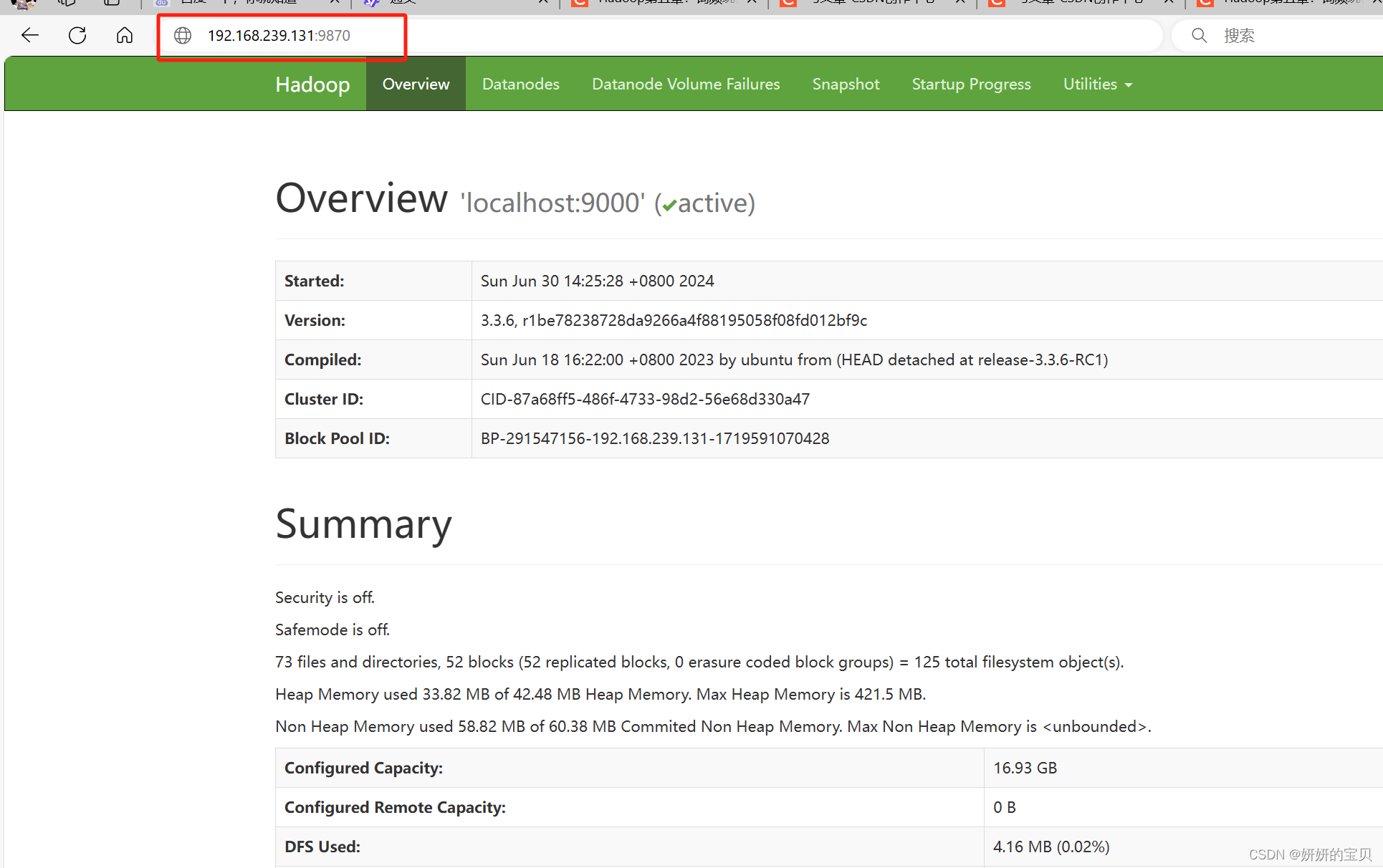
这是在HDFS文件系统上的文件

在虚拟机上使用命令同样也能看到

2.3 文件上传
网上随便找一篇英语短文,作为单词统计的文档

[root@hadoop ~]# mkdir /wordcount
[root@hadoop ~]# cd /wordcount/
[root@hadoop wordcount]# vim words2.txt
英语文章实例
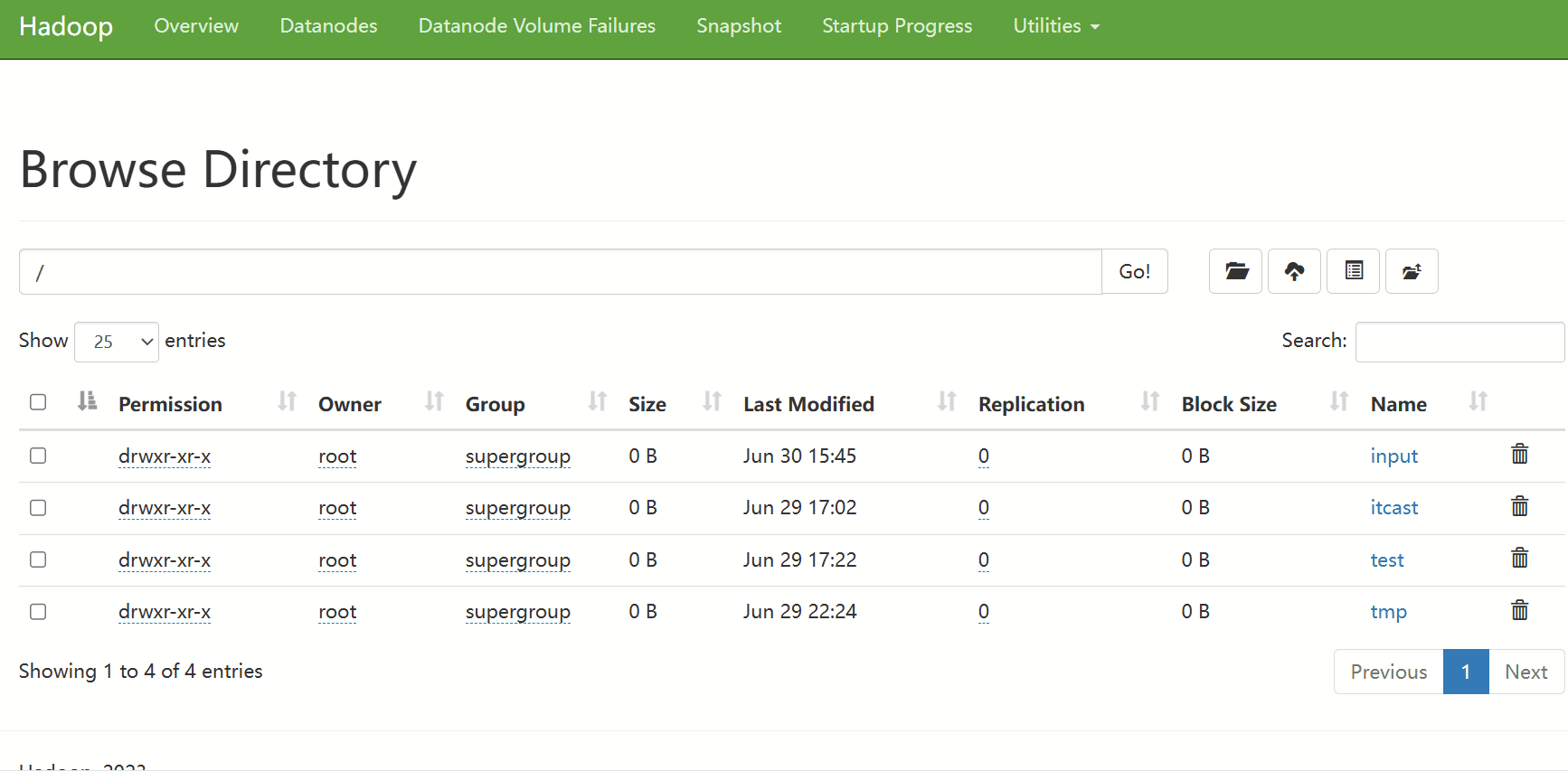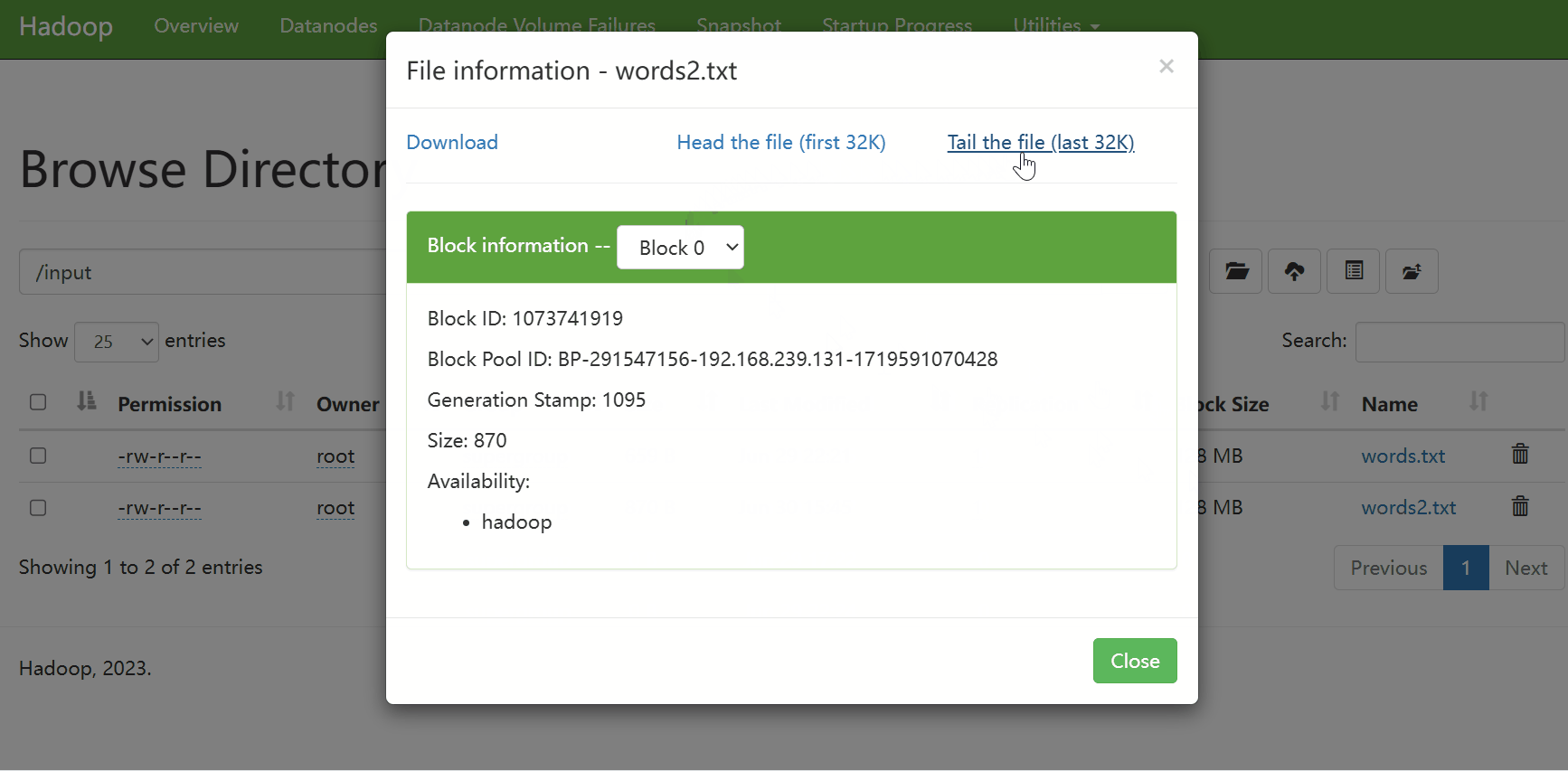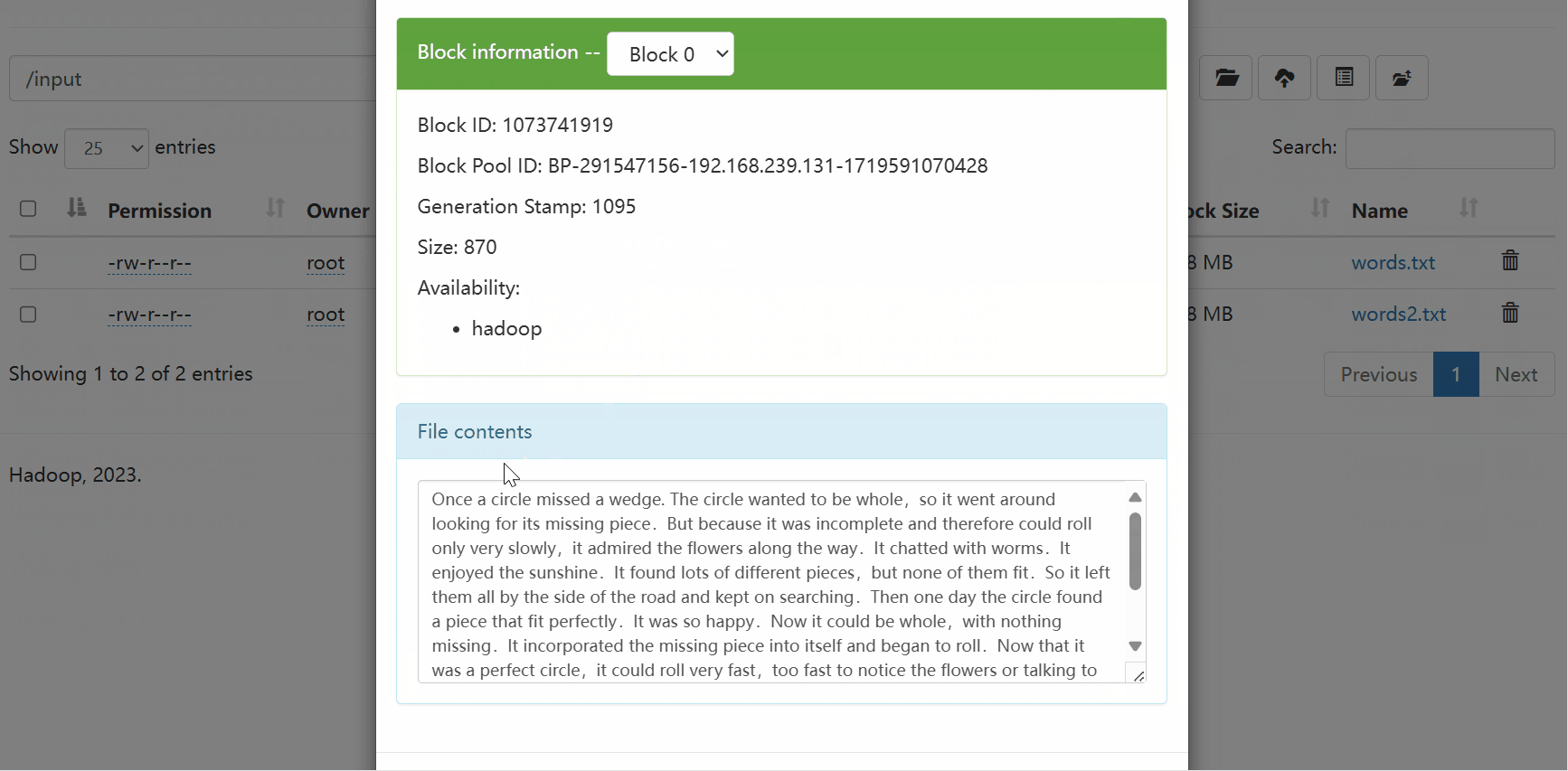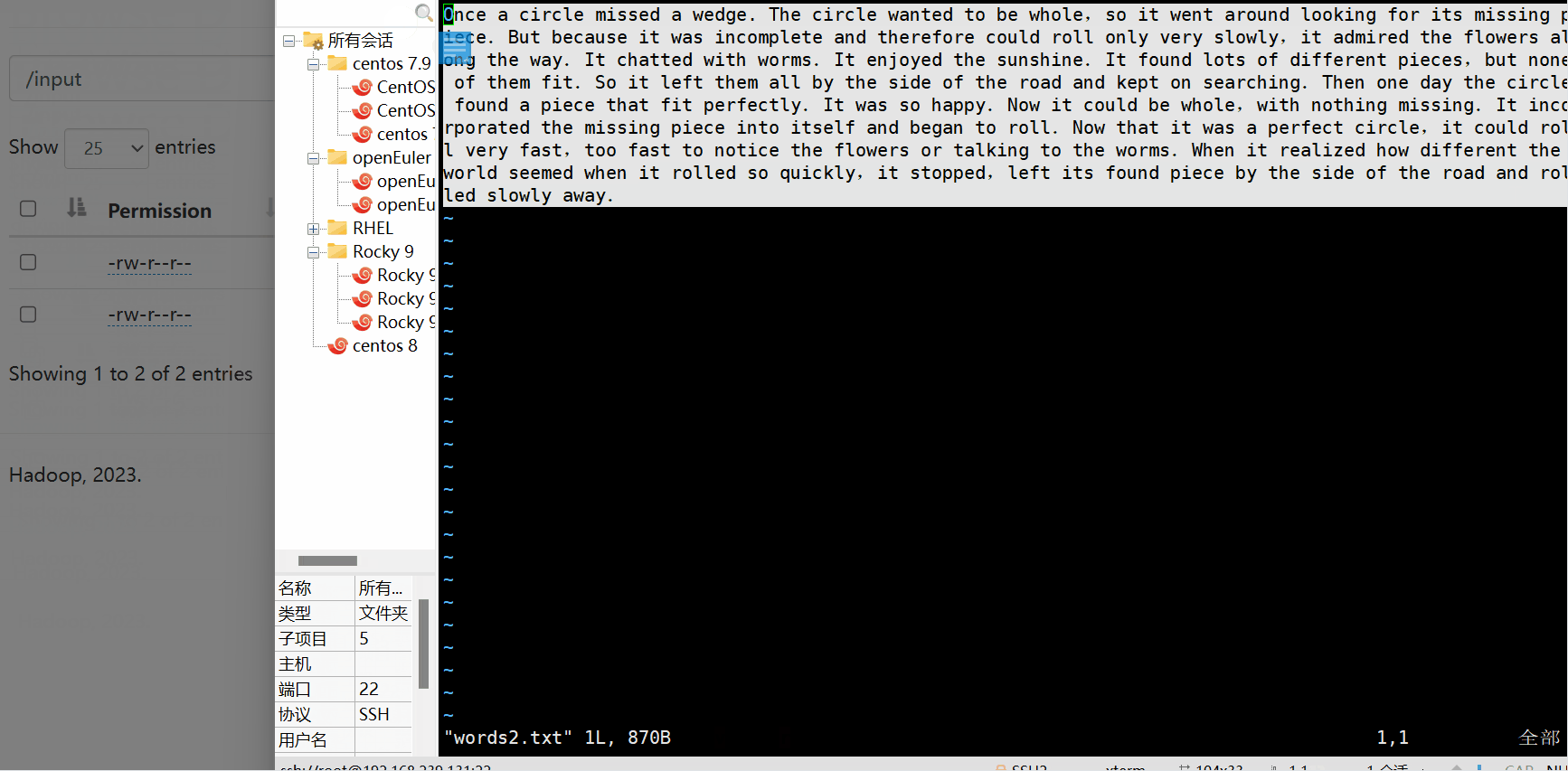
Once a circle missed a wedge. The circle wanted to be whole,so it went around looking for its missing piece.But because it was incomplete and therefore could roll only very slowly,it admired the flowers along the way.It chatted with worms.It enjoyed the sunshine.It found lots of different pieces,but none of them fit.So it left them all by the side of the road and kept on searching.Then one day the circle found a piece that fit perfectly.It was so happy.Now it could be whole,with nothing missing.It incorporated the missing piece into itself and began to roll.Now that it was a perfect circle,it could roll very fast,too fast to notice the flowers or talking to the worms.When it realized how different the world seemed when it rolled so quickly,it stopped,left its found piece by the side of the road and rolled slowly away.

在HDFS文件系统中根目录创建 input 目录
我这里目录已经创建过了所以会显示已存在
[root@hadoop wordcount]# hadoop fs -mkdir /input
mkdir: `/input': File exists

上传文件到HDFS文件系统
[root@hadoop wordcount]# hadoop fs -put /wordcount/words2.txt /input浏览器查看是否上传成功
2.4 配置hadoop的classpath
[root@hadoop wordcount]# hadoop classpath
/opt/hadoop/etc/hadoop:/opt/hadoop/share/hadoop/common/lib/*:/opt/hadoop/share/hadoop/common/*:/opt/hadoop/share/hadoop/hdfs:/opt/hadoop/share/hadoop/hdfs/lib/*:/opt/hadoop/share/hadoop/hdfs/*:/opt/hadoop/share/hadoop/mapreduce/*:/opt/hadoop/share/hadoop/yarn:/opt/hadoop/share/hadoop/yarn/lib/*:/opt/hadoop/share/hadoop/yarn/*
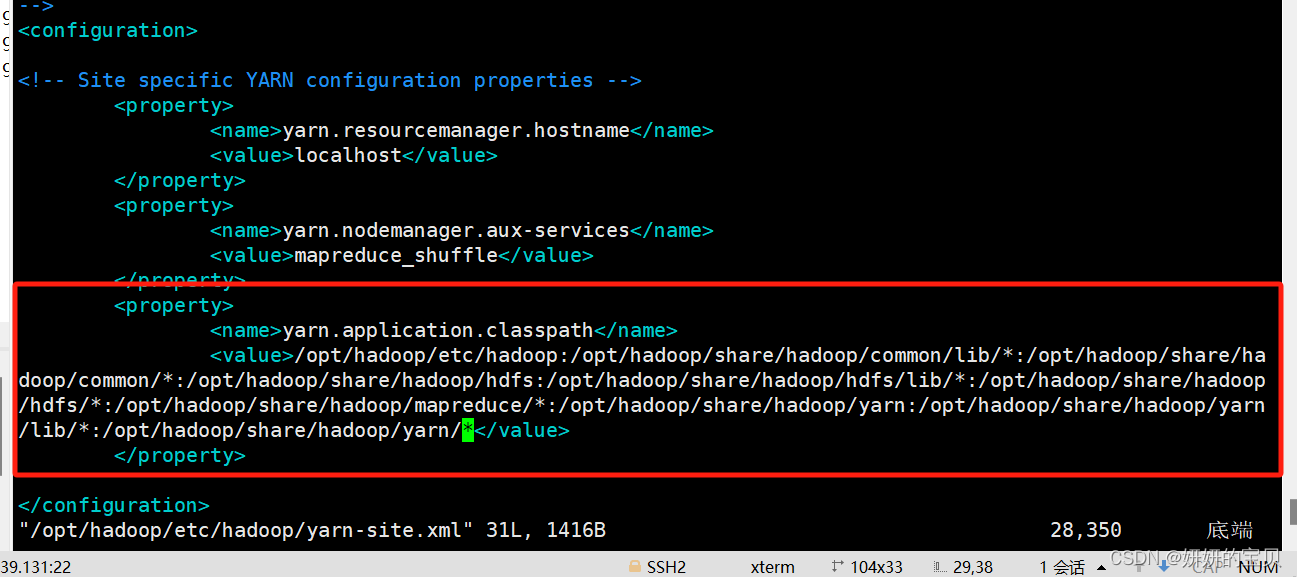
[root@hadoop wordcount]# vim /opt/hadoop/etc/hadoop/yarn-site.xml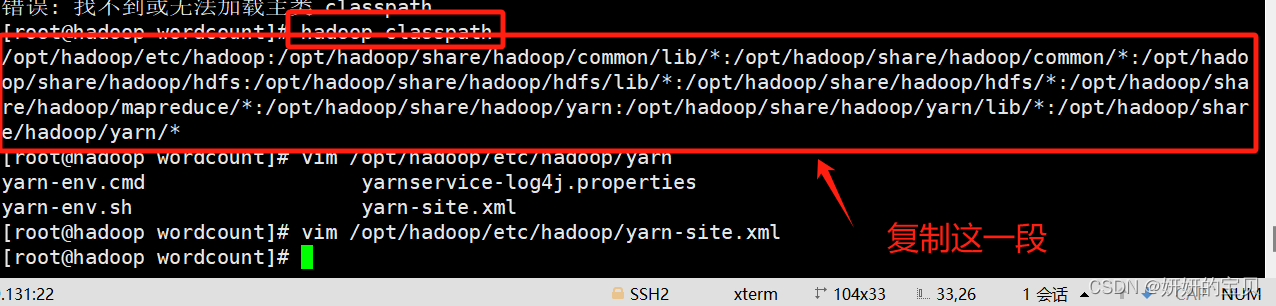
3 词频统计
在文件系统上有了文章可以开始词频统计了
3.1 方法一:使用hadoop自带的jar包文件
查看jar包放在哪个目录下了
[root@hadoop wordcount]# find $HADOOP_HOME/ -name mapreduce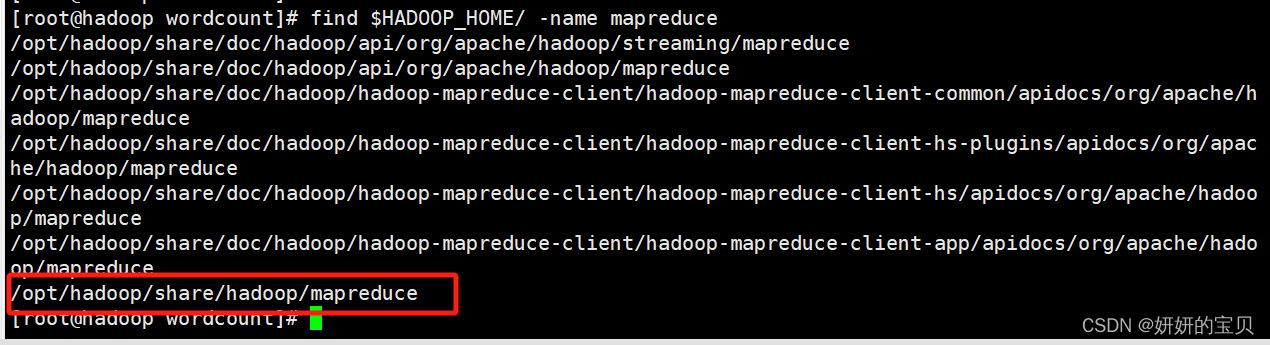
移动到这个目录下
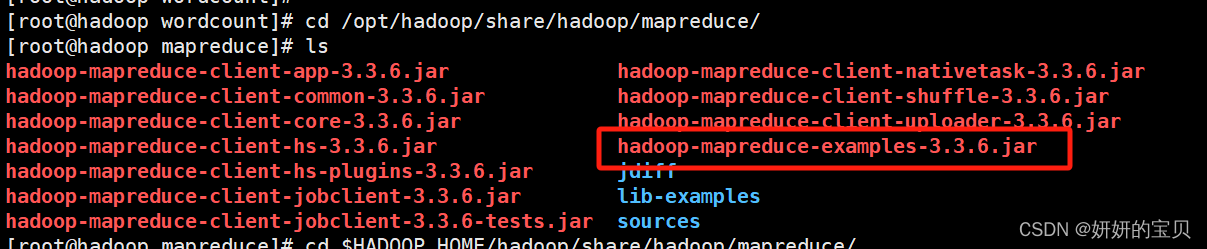
[root@hadoop wordcount]# cd /opt/hadoop/share/hadoop/mapreduce/
[root@hadoop mapreduce]# ls
hadoop-mapreduce-client-app-3.3.6.jar hadoop-mapreduce-client-nativetask-3.3.6.jar
hadoop-mapreduce-client-common-3.3.6.jar hadoop-mapreduce-client-shuffle-3.3.6.jar
hadoop-mapreduce-client-core-3.3.6.jar hadoop-mapreduce-client-uploader-3.3.6.jar
hadoop-mapreduce-client-hs-3.3.6.jar hadoop-mapreduce-examples-3.3.6.jar
hadoop-mapreduce-client-hs-plugins-3.3.6.jar jdiff
hadoop-mapreduce-client-jobclient-3.3.6.jar lib-examples
hadoop-mapreduce-client-jobclient-3.3.6-tests.jar sources
找到一个叫hadoop-mapreduce-examples-3.3.6.jar 的文件
这个文件是hadoop自带的专门做词频统计的jar包
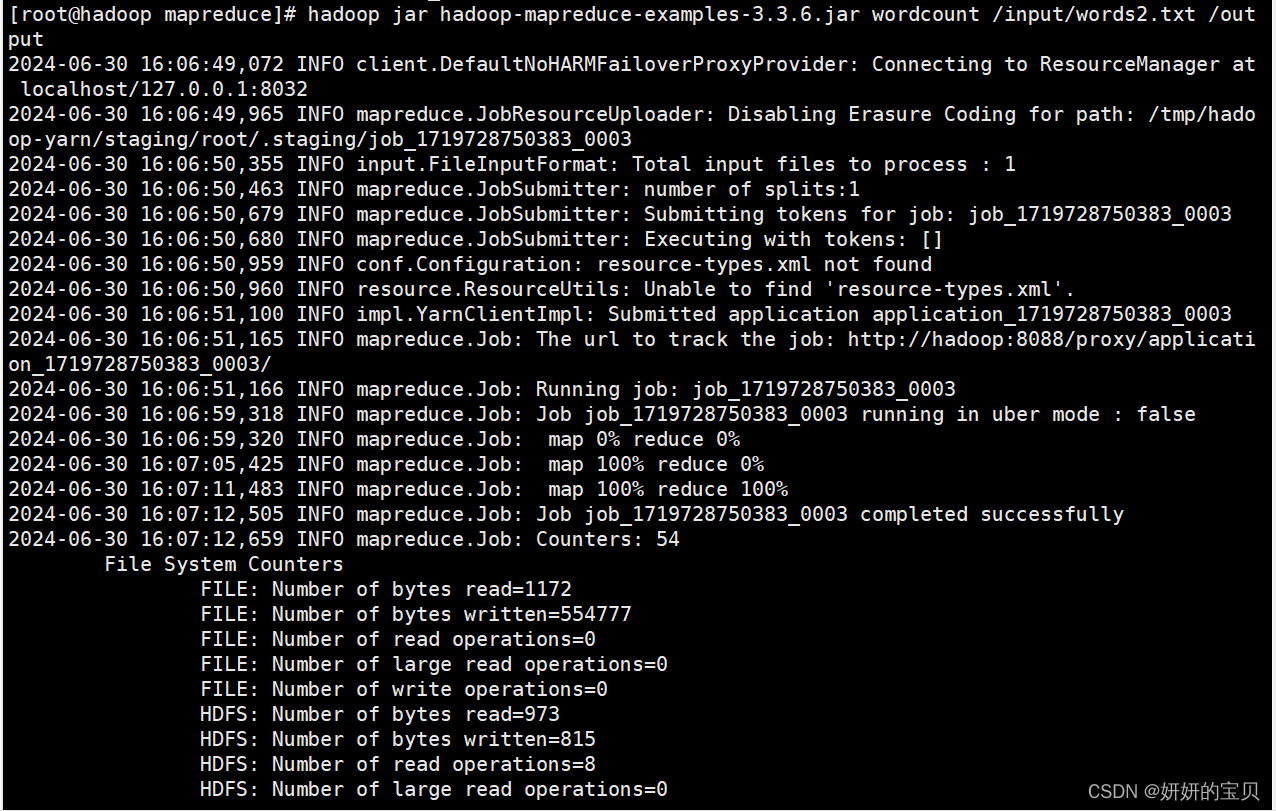
选择jar包运行java程序对文章进行词频统计
[root@hadoop mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.6.jar wordcount /input/words2.txt /output
查看根目录多出了个output目录,点击他
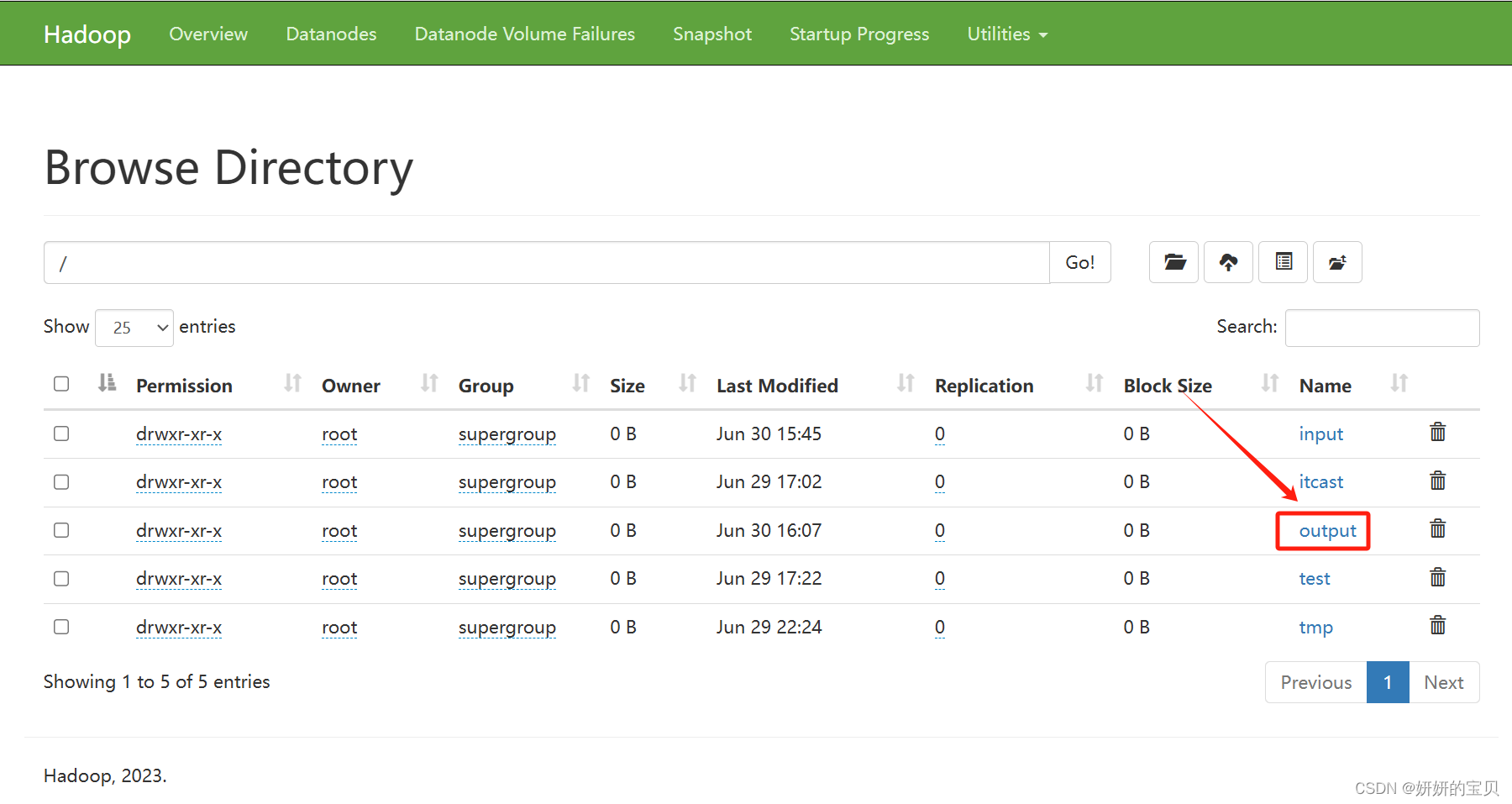
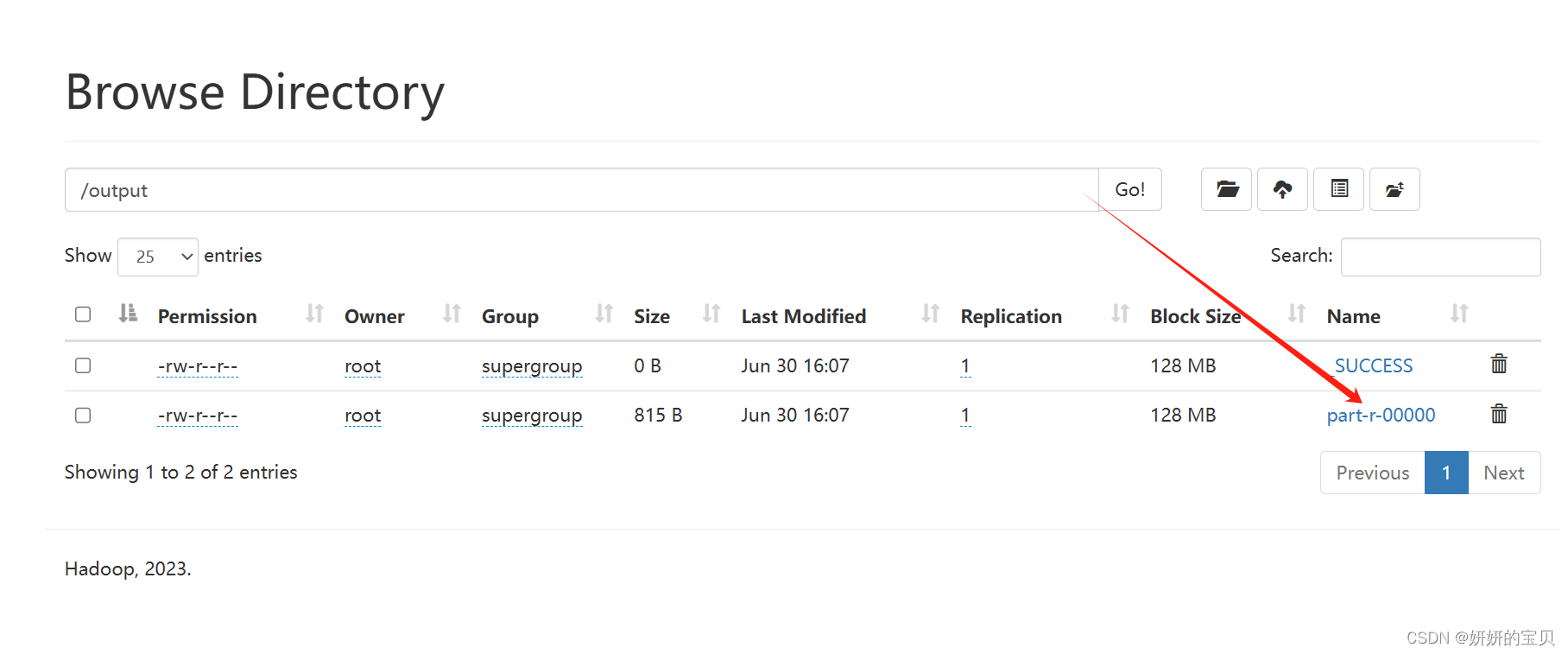
得出结果
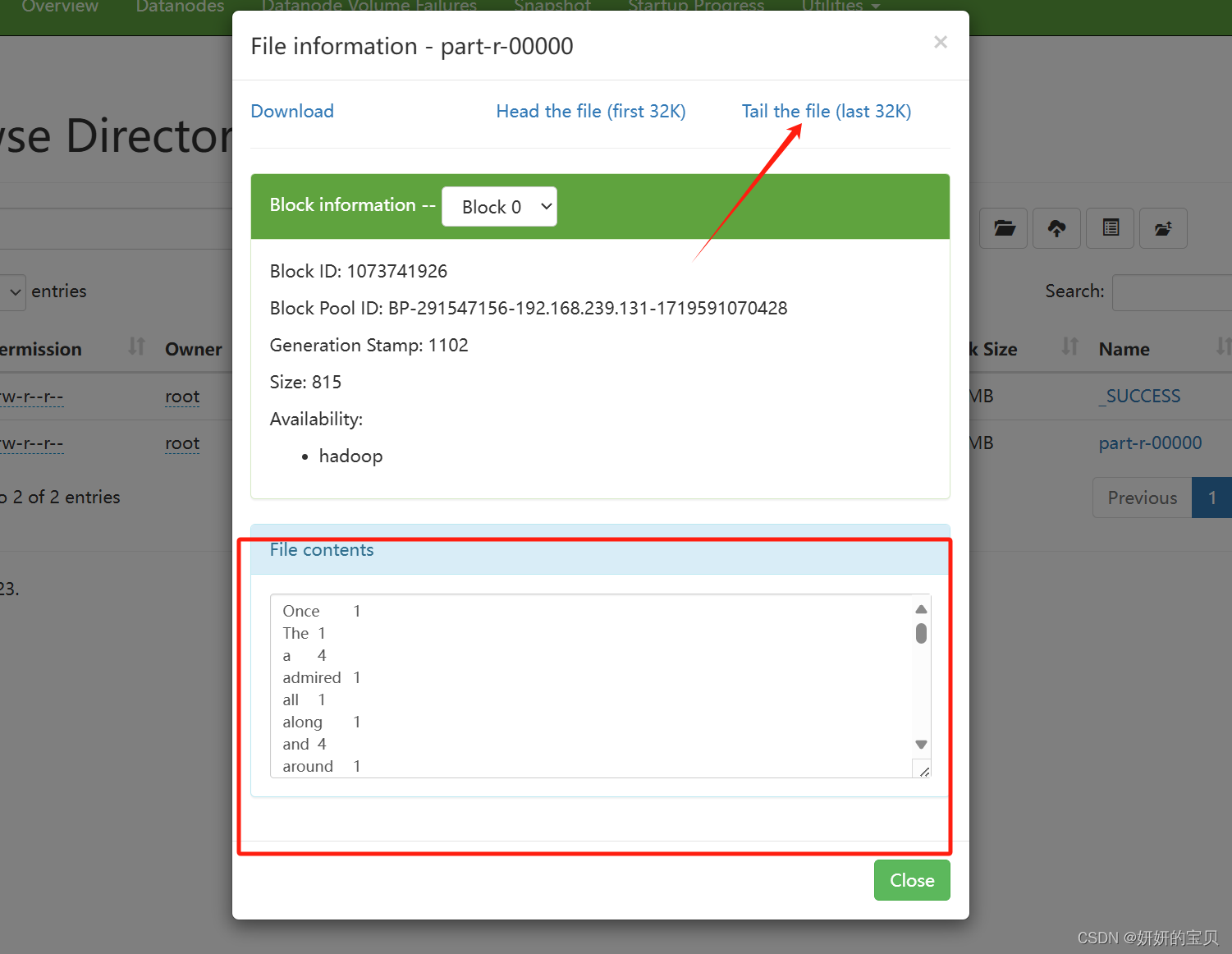
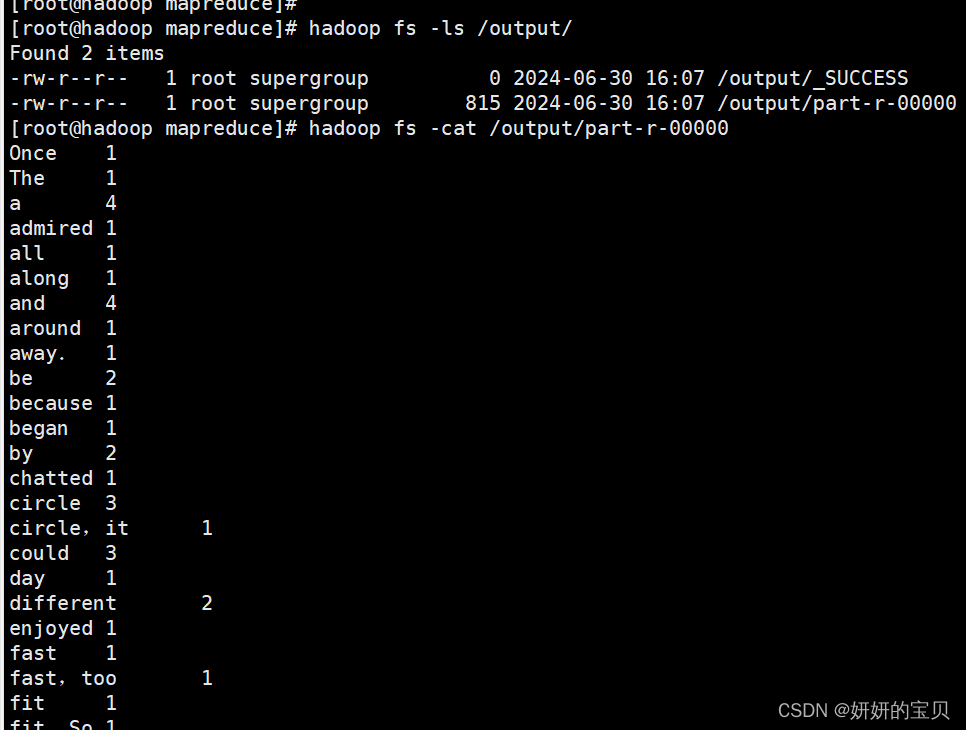
同样在虚拟机上也可查看
3.2 方法二:编写java程序打包jar包
使用的软件为idea
新建项目
将以下代码插入pom.xml 中
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>插入之后点击

添加以下内容
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n编写java类
WordCountDriver ---主类
WordCountMapper
WordCountReducer
代码如下
WordCountDriver
package com.hadoop.mapreducer.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1.获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.设置jar包路径
job.setJarByClass(WordCountDriver.class);
//3.关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4.设置map输出kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5.设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.设置输入路径和输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7.提交job
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}WordCountMapper
package com.hadoop.mapreducer.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable,Text,Text, IntWritable> {
//为了节省空间,将k-v设置到函数外
private Text outK=new Text();
private IntWritable outV=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//获取一行输入数据
String line = value.toString();
//将数据切分
String[] words = line.split(" ");
//循环每个单词进行k-v输出
for (String word : words) {
outK.set(word);
//将参数传递到reduce
context.write(outK,outV);
}
}
}
WordCountReducer
package com.hadoop.mapreducer.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
//全局变量输出类型
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { //设立一个计数器
int sum=0;
//统计单词出现个数
for (IntWritable value : values) {
sum+=value.get();
}
//转换结果类型
outV.set(sum);
//输出结果
context.write(key,outV);
}
}可能会出现报红
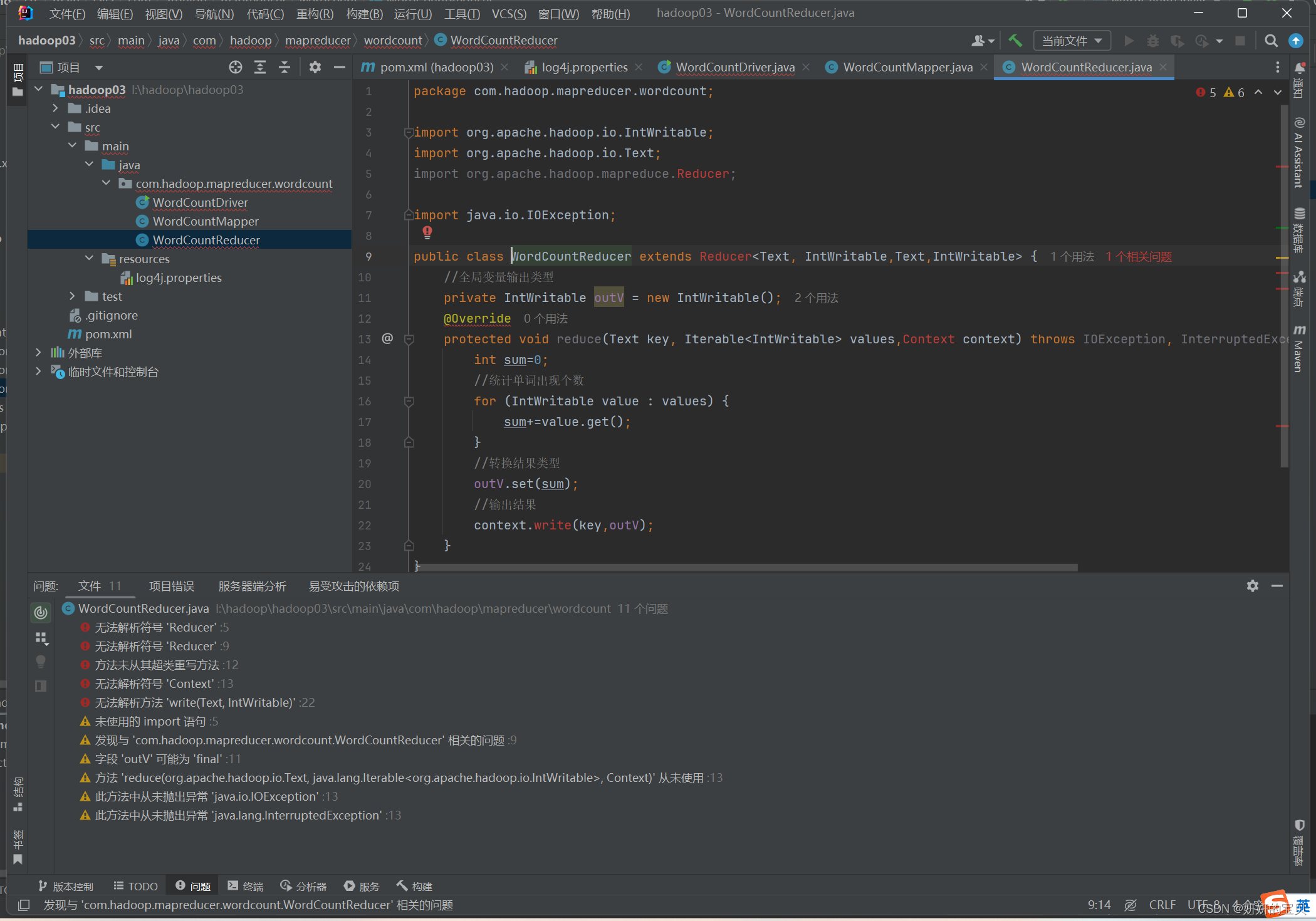
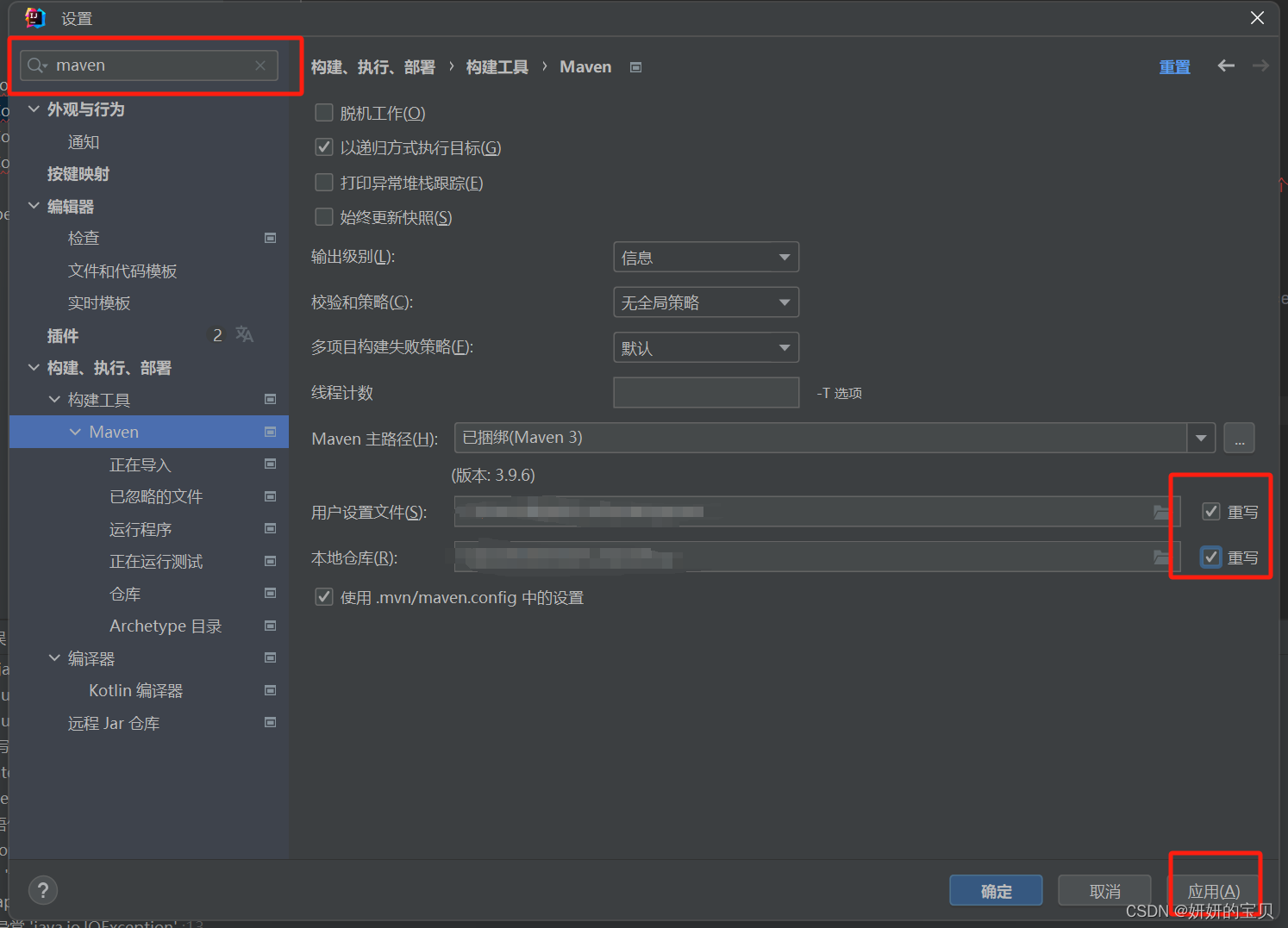
打包jar包
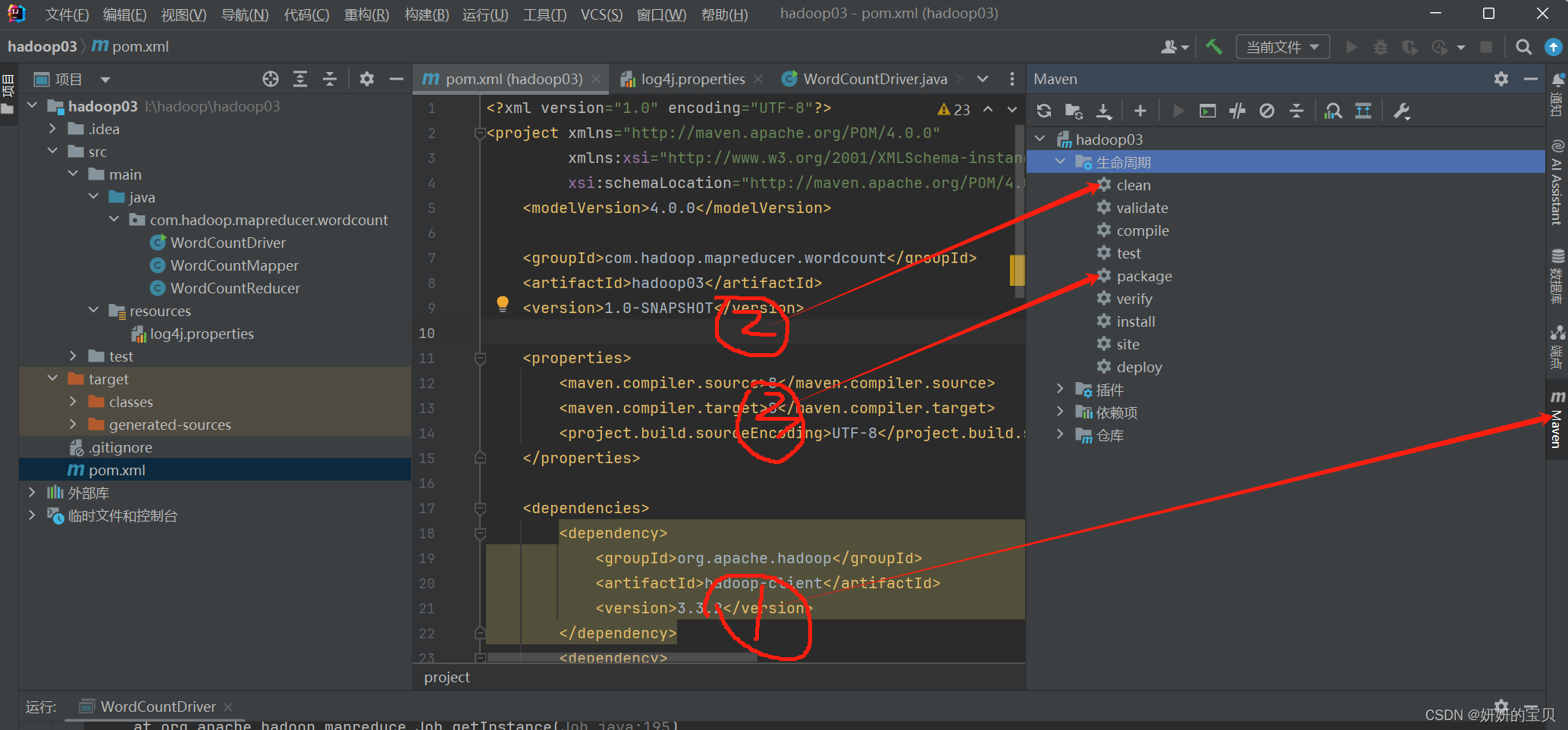
这时候会出现两个jar包使用第一个就可以了
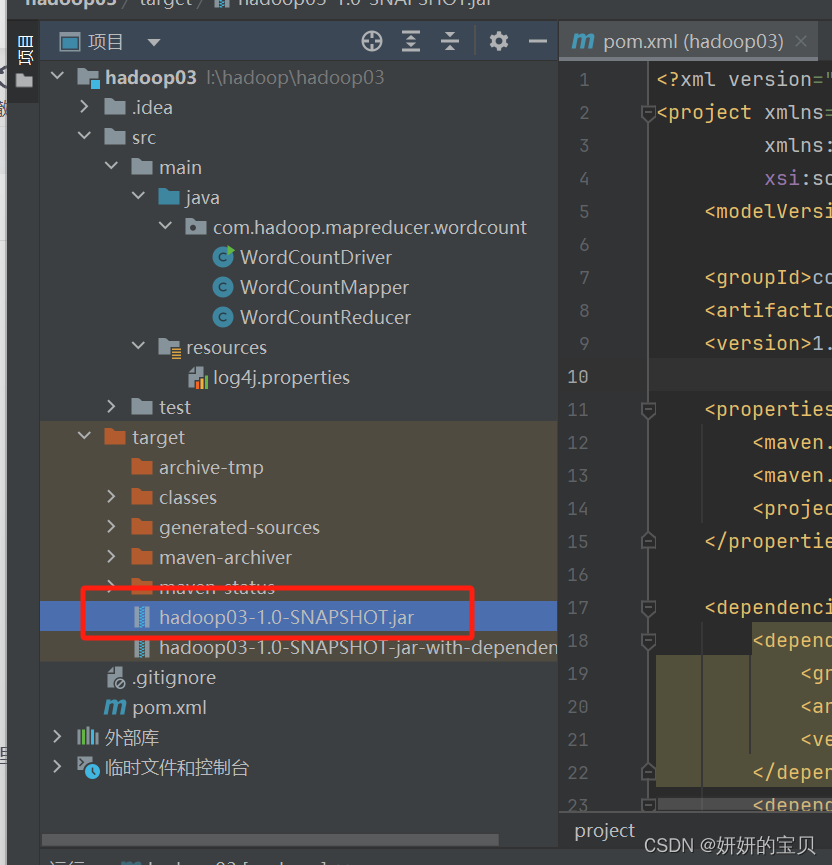
将jar包移动到linux下
[root@hadoop wordcount]# hadoop jar hadoop03-1.0-SNAPSHOT.jar com.hadoop.mapreducer.wordcount.WordCountDriver /input/words2.txt /output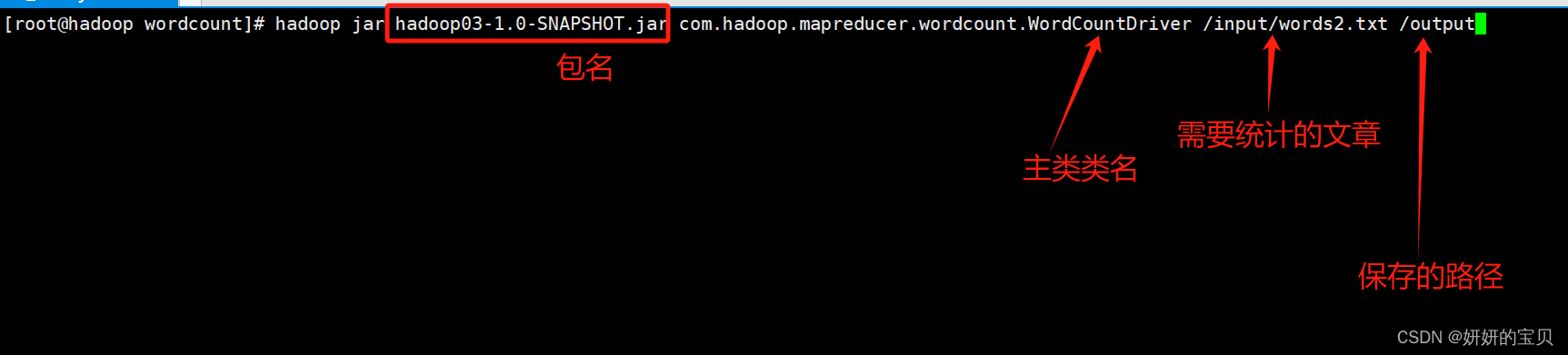
执行成功
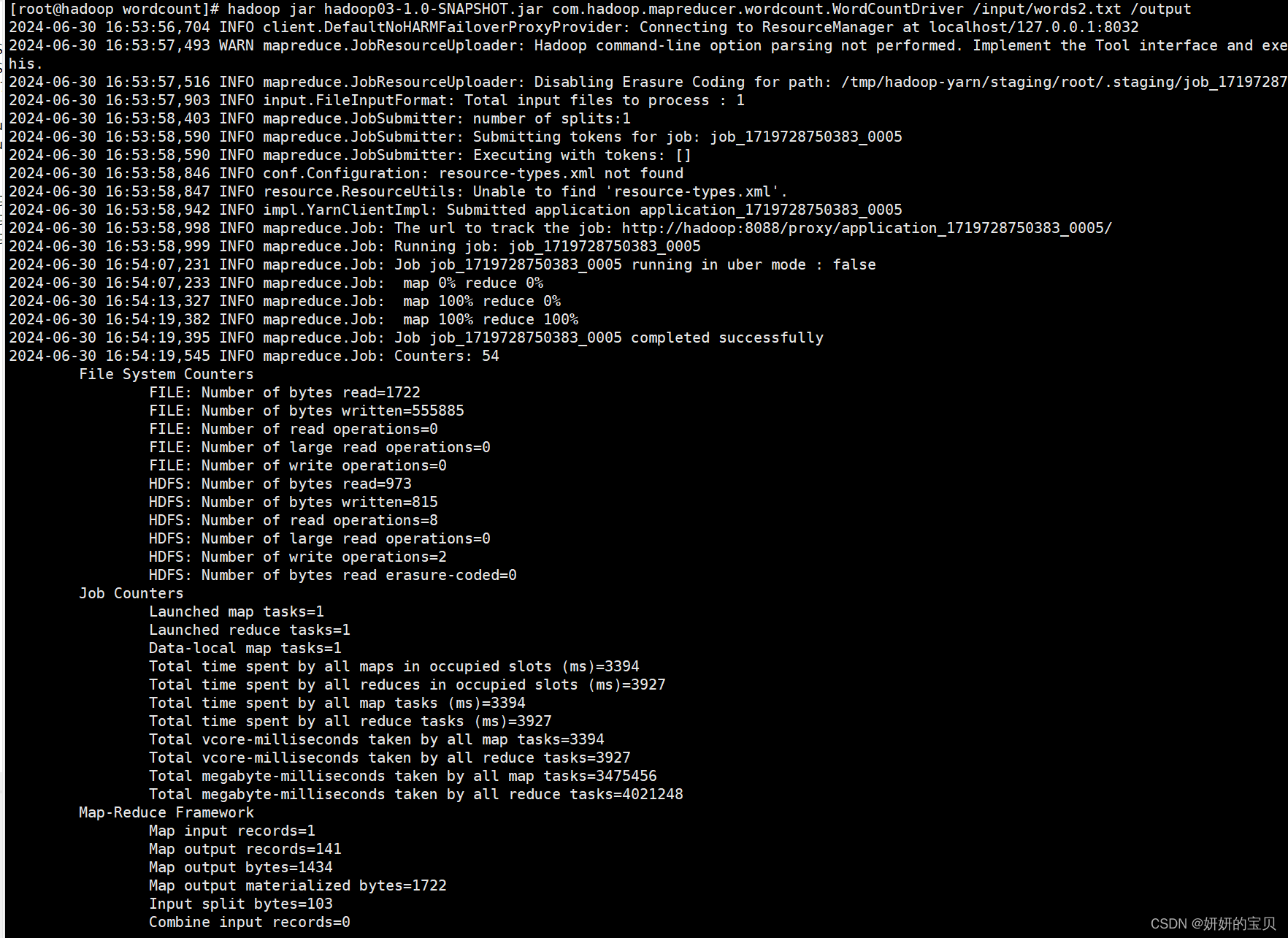
动图演示